El aprendizaje no supervisado, una rama del aprendizaje automático, permite que los algoritmos identifiquen patrones en datos no etiquetados.
Su desarrollo es cada vez más visible y va de la mano del crecimiento del Machine Learning, cuyos mercados están en alza. Según The Insght Partners, se proyecta que el tamaño del mercado de aprendizaje automático alcance los 425.370 millones de dólares en 2031, frente a los 37.920 millones de dólares en 2023. Se espera que el mercado registre una CAGR del 35,2 % entre 2023 y 2031.
“Es probable que la creciente integración de la inteligencia artificial y el aumento de las aplicaciones en el sector sanitario sigan siendo tendencias clave del mercado de aprendizaje automático”, revelan desde la organización.

Según la última actualización de la Guía Mundial de Inversión en IA e IA Generativa 2024 V2 de IDC, la inversión global en IA —impulsada en parte por algoritmos no supervisados y generativos— crecerá de 235.000 millones de dólares en 2024 a más de 631.000 millones en 2028 (CAGR 27%).
Este crecimiento influye y es esencial en áreas como la biomedicina, la ciberseguridad y la minería de datos, donde la capacidad de descubrir patrones ocultos en grandes volúmenes de datos está transformando industrias enteras.
Por ejemplo, en la biomedicina se utiliza para descubrir nuevas relaciones entre genes y enfermedades. Un estudio realizado por investigadores de diversas universidades demostraron que un enfoque totalmente no supervisado mejora la segmentación de anomalías sin datos etiquetados.
Mientras que en el caso de la ciberseguridad se aplica para detectar patrones inusuales que podrían indicar actividades maliciosas.
Para entenderlo mejor, es posible establecer algunas distinciones con el aprendizaje supervisado. En este último, por ejemplo, se proporciona un conjunto de datos etiquetado para entrenar un modelo.
Aquí radica la principal diferencia, ya que en el aprendizaje no supervisado el modelo debe encontrar patrones y relaciones en los datos por sí solo.
El clustering sigue siendo una técnica clave dentro del aprendizaje no supervisado, especialmente con el uso de algoritmos más avanzados como K-Means++, DBSCAN y Mean Shift, que mejoran la precisión al manejar grandes volúmenes de datos complejos.
Empresas de telecomunicaciones como AT&T utilizan clustering para segmentar grandes volúmenes de datos de clientes y optimizar sus ofertas personalizadas. Además, el clustering es fundamental para la detección de fraudes en las transacciones bancarias, donde la identificación de patrones irregulares puede evitar grandes pérdidas financieras.
De hecho, el Departamento del Tesoro de EE. UU. reportó, por ejemplo, en 2024, que el uso de inteligencia artificial, incluyendo clustering, permitió prevenir y recuperar más de 4.000 millones de dólares en pagos fraudulentos en un solo año.
El objetivo del clustering es agrupar datos similares en clústeres homogéneos. Nuevas técnicas como Spectral Clustering han demostrado ser útiles para datos no lineales, permitiendo obtener una mayor precisión en la agrupación de datos complejos.
Índice de temas
Diferencia entre aprendizaje supervisado y no supervisado
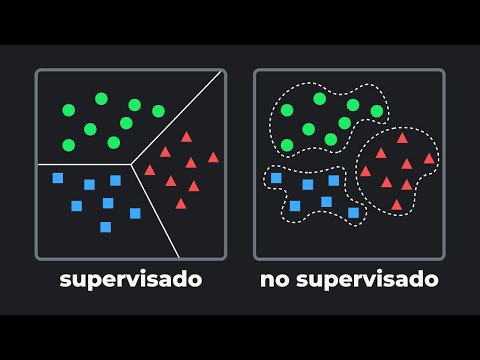
La diferencia fundamental entre el aprendizaje supervisado y el aprendizaje no supervisado radica en cómo se manejan los datos.
En el aprendizaje supervisado, los algoritmos se entrenan utilizando un conjunto de datos previamente etiquetados, es decir, cada entrada está acompañada de una salida o resultado esperado.
Esto permite al modelo aprender de manera guiada, ajustando sus predicciones con base en ejemplos correctos. Es comúnmente utilizado en tareas como la clasificación de correos electrónicos o la predicción de ventas.
Por otro lado, en el aprendizaje no supervisado, el modelo no tiene acceso a datos etiquetados. En lugar de ello, debe descubrir patrones y relaciones ocultas en los datos por sí mismo.
Este enfoque es crucial en situaciones donde la estructura de los datos no es obvia, como en la segmentación de clientes o la detección de anomalías en la ciberseguridad.
La capacidad de identificar patrones sin intervención humana lo convierte en una herramienta valiosa para analizar grandes volúmenes de datos no estructurados.
| Criterio | Aprendizaje Supervisado | Aprendizaje No Supervisado | Ejemplos de Aplicaciones Empresariales |
|---|---|---|---|
| Dataset | Utiliza un conjunto de datos previamente etiquetado. | No requiere conjuntos de datos etiquetados, trabaja con datos sin etiquetas. | Supervisado: Detección de fraudes en transacciones bancarias, diagnóstico médico asistido por IA. |
| Proceso | El modelo aprende a partir de los ejemplos etiquetados para predecir una etiqueta o categoría en los datos nuevos. | El modelo busca patrones o relaciones ocultas entre los datos sin etiquetas. | No Supervisado: Segmentación de clientes en e-commerce, detección de anomalías en la cadena de suministro. |
| Complejidad del Modelo | Generalmente más sencillo y con menos riesgo de sobreajuste si los datos están bien etiquetados. | Puede ser más complejo debido a la naturaleza exploratoria del análisis. | Supervisado: Clasificación de imágenes, predicción de precios de activos financieros. |
| Tiempo de Entrenamiento | Más rápido, pero depende de la cantidad de datos etiquetados. | Suele ser más lento, ya que el modelo tiene que identificar patrones de manera autónoma. | No Supervisado: Optimización de inventarios con clustering, mejora en la gestión de recursos mediante reducción de dimensionalidad. |
| Errores Comunes | Puede sobreajustarse si los datos están sobreentrenados o si no hay suficientes ejemplos. | Puede no encontrar patrones útiles si no se preprocesan correctamente los datos. | Supervisado: Diagnóstico predictivo en salud, sistemas de recomendación. |
| Aplicaciones Típicas | Clasificación, regresión, predicción de valores futuros. | Clustering, reducción de dimensionalidad, detección de anomalías. | No Supervisado: Marketing digital, descubrimiento de patrones en datos no estructurados, personalización de ofertas. |
Tipos de aprendizaje no supervisado
Tal como mencionamos, el aprendizaje no supervisado es una técnica de aprendizaje automático que tiene por objetivo descubrir patrones ocultos en los datos sin la necesidad de que estos estén etiquetados.
En este apartado mencionaremos los tipos de aprendizaje no supervisado:
Clustering
Este método, como K-Means y DBSCAN, sigue siendo esencial para agrupar datos similares. Hoy en día, versiones mejoradas como K-Means++ han optimizado el proceso de inicialización, evitando resultados subóptimos.
Reducción de dimensionalidad
Técnicas como t-SNE y PCA (Análisis de Componentes Principales) permiten visualizar datos en espacios de baja dimensionalidad, lo que es crucial para el análisis de grandes volúmenes de datos en áreas como la genética y la astrofísica.
Detección de anomalías
Algoritmos como Isolation Forest y One-Class SVM han ganado popularidad en la detección de anomalías, permitiendo la identificación rápida de eventos inusuales en la ciberseguridad y el mantenimiento predictivo.

Ventajas del aprendizaje M2M y su aplicación práctica
El aprendizaje de máquina a máquina (M2M, por sus siglas en inglés) es una variante del aprendizaje automático que tiene que ver con el desarrollo de agentes inteligentes que pueden aprender y tomar decisiones de manera autónoma. M2M, este se ha complementado con tecnologías emergentes como el Internet de las Cosas (IoT), donde los dispositivos autónomos pueden comunicarse e intercambiar datos en tiempo real, optimizando procesos industriales y logísticos
Entre las principales ventajas de este tipo de aprendizaje destaca la reducción del costo humano en la toma de decisiones. Esto se debe a que ya no es necesario que haya una persona dirigiendo la actividad de las máquinas, las cuales pueden actuar por sí mismas.
Técnicas de aprendizaje no supervisado y tipos de algoritmos de agrupación en clústeres
Existen varios tipos de algoritmos de agrupación en clústeres que se utilizan en el aprendizaje no supervisado. En este apartado, nos encargaremos de mencionar los más conocidos.
K-means
Se trata de uno de los métodos de aprendizaje de clustering más populares y su funcionamiento se basa en la agrupación de datos en un número K de grupos.
K es un número que está previamente definido por el usuario. De esa manera, el algoritmo de K-Means sigue siendo popular, pero técnicas como K-Means++ han optimizado su proceso de inicialización, mejorando significativamente su capacidad de evitar soluciones subóptimas y acelerando la convergencia del modelo
Clustering jerárquico
Se trata de un método de minería de datos que consiste en la agrupación de los mismos acordes a la distancia de cada uno. Uno de los objetivos de este método es que los datos que se encuentran dentro de un clúster sean lo más similares entre sí.
Existen dos tipos de clustering jerárquico: el aglomerativo y el divisivo. El clustering jerárquico aglomerativo sigue siendo un método importante, aunque los nuevos algoritmos como HDBSCAN han mejorado la robustez frente a datos ruidosos y proporcionan una mayor precisión en la identificación de agrupaciones en conjuntos de datos complejos
Por otra parte, en el clustering jerárquico divisivo, se comienza con un solo cluster que contiene todos los puntos de datos y luego se van dividiendo en clusters más pequeños.
DBSCAN
DBSCAN es otra de las técnicas de clustering más populares que existen. Consiste en una agrupación espacial de aplicaciones con ruido en la que se tiene en cuenta la densidad.
Su principal objetivo es encontrar clusters cuyas formas sean arbitrarias. Mediante su algoritmo, DBSCAN agrupa los puntos de datos que están cerca unos de otros en el espacio, y entiende que los puntos que están más alejados son ruidos, su precisión se ha mejorado con la incorporación de versiones como HDBSCAN, que ajusta automáticamente el número de clústeres y maneja mejor los datos con ruido, optimizando su capacidad para encontrar patrones complejos
Mean shift
Por último, debemos mencionar a Mean Shift, que comparte con K-Means la característica de ser iterativo. Una de sus utilidades es la de encontrar áreas densas de puntos de datos y su aplicación ha mejorado con técnicas más recientes que permiten adaptarse mejor a variaciones en la distribución de datos
Algoritmos Basados en Densidad (OPTICS)
OPTICS (Ordenar Puntos para Identificar la Estructura de Agrupación) es una evolución de DBSCAN que está diseñada para trabajar mejor con datos de clústeres que tienen diferentes densidades. Mientras que DBSCAN define clústeres a través de una densidad fija, OPTICS ajusta esa densidad en tiempo real, lo que permite identificar grupos de diferentes formas y tamaños con mayor precisión, especialmente en conjuntos de datos con ruido.
Gaussian Mixture Models (GMM)
Los modelos de mezcla gaussiana son más flexibles que K-Means, ya que permiten que los datos se agrupen en formas más complejas. En lugar de limitarse a clústeres con bordes definidos, GMM asume que los datos provienen de una mezcla de distribuciones gaussianas, lo que lo hace ideal para datos que no se agrupan de manera estrictamente esférica, sino más bien elíptica o alargada.
Spectral Clustering
Este método es especialmente útil cuando los datos no se agrupan en líneas rectas o formas predefinidas. Spectral Clustering analiza las relaciones de los datos mediante un grafo de similitud y utiliza esta información para crear clústeres no lineales. Es particularmente valioso en situaciones donde otros algoritmos como K-Means no logran capturar la complejidad de las relaciones entre los datos.
Clustering Basado en Modelos (Expectation-Maximization)
El algoritmo de Expectation-Maximization (EM) es una técnica que se utiliza para encontrar patrones en datos donde existen variables ocultas o no observables. Este método es eficaz cuando se asume que los datos provienen de varias distribuciones y es necesario estimar los parámetros de esas distribuciones. A menudo se utiliza en aplicaciones donde los modelos estadísticos son complejos y requieren una aproximación más sofisticada.
Mejores casos de uso para el aprendizaje no supervisado
Antes de comenzar a describir cuáles son los mejores casos de uso para el aprendizaje no supervisado, hay que decir que generalmente se utiliza para tareas más complejas que el aprendizaje supervisado.
Algunas de las aplicaciones del aprendizaje no supervisado son la segmentación de conjuntos de datos por características compartidas, como en el análisis de comportamiento del consumidor en empresas de retail.
Además, en la industria financiera, se usa para detectar fraudes al identificar patrones anómalos en las transacciones, lo que permite a los bancos prevenir actividades fraudulentas antes de que ocurran.
Otro uso relevante es en el campo de la medicina personalizada, donde los algoritmos agrupan pacientes en función de sus respuestas a diferentes tratamientos, mejorando la eficiencia de los cuidados médicos.
El aprendizaje no supervisado tiene aplicaciones extendidas más allá del análisis de mercado, incluyendo detección de fraudes, segmentación de clientes y predicción de comportamientos futuros basados en patrones de datos históricos, porque permite descubrir patrones de compra u otro tipo de comportamientos que el consumidor pueda tener.
Asimismo, es utilizada en la segmentación de clientes, ya que ofrece la posibilidad de agruparlos según sus características y encontrar relaciones entre ellos. También puede ser muy útil para la detección de fraudes por su capacidad de identificar patrones anormales en las transacciones.
El aprendizaje no supervisado está transformando la forma en que las empresas gestionan sus operaciones, optimizan recursos y comprenden a sus clientes. Un ejemplo clave es su uso en la detección de anomalías en la cadena de suministro, donde algoritmos de clustering como DBSCAN identifican patrones inusuales en la producción o distribución.
Tal visión coincide con el análisis del World Economic Forum sobre cómo la IA pasará “del hype a soluciones globales” mediante ecosistemas colaborativos y aprendizaje autónomo. Esto permite a las empresas reaccionar rápidamente a problemas, como demoras o fallos de stock, que podrían afectar la eficiencia operativa.
Esto permite a las empresas reaccionar rápidamente a problemas, como demoras o fallos de stock, que podrían afectar la eficiencia operativa.
En el sector del e-commerce, el aprendizaje no supervisado está revolucionando la segmentación de clientes. Empresas como Amazon y otros grandes minoristas utilizan clustering para agrupar a sus clientes según patrones de comportamiento de compra, lo que permite crear ofertas personalizadas y aumentar la conversión.
Además, en logística, la reducción de dimensionalidad, como el uso de PCA, se está empleando para optimizar la gestión de inventarios, identificando productos de alta rotación y previendo tendencias de demanda, lo que mejora la eficiencia de los almacenes y reduce costos operativos.
El estudio AI Risk and Threat Taxonomy del Instituto Nacional de Estándares y Tecnología (NIST, por sus siglas en inglés) sitúa el aprendizaje no supervisado entre las técnicas que deben evaluarse en cualquier plan de gestión de riesgos de IA, por los vectores de ataque específicos que introduce.
Entrenamiento sin etiquetar para desarrollar características útiles
Tal como hemos descrito hasta ahora, una de las características de este tipo de aprendizaje automático es que sus algoritmos se entrenan con datos no etiquetados. Esto facilita la implementación del modelo.
En el aprendizaje no supervisado, los nuevos datos son analizados con el objetivo de establecer conexiones significativas entre las entradas y las salidas predeterminadas. De esta manera se pueden detectar patrones y categorizar los datos.
Como consecuencia del entrenamiento sin etiquetar, hay ciertas características útiles que tiene este método, como por ejemplo la posibilidad de agrupar artículos de noticias en diferentes segmentos según de que se trate cada uno.
Además, permite acceder a funciones más avanzadas, como la comprensión del significado y del sentido de un artículo determinado mediante el procesamiento del lenguaje natural.
En resumen, el aprendizaje no supervisado sigue evolucionando con la incorporación de nuevas técnicas como los Autoencoders y las Redes Generativas Antagónicas (GANs), que permiten encontrar patrones complejos y descubrir estructuras de datos más avanzadas.
Tal como se explica en el capítulo de Aprendizaje no supervisado del curso 6.390 (Spring 2024) del MIT, técnicas como los autoencoders permiten comprimir los datos y “revelar factores latentes” que luego mejoran la interpretación y la eficacia de modelos posteriores. Estos son un tipo de red neuronal artificial utilizada para aprender codificaciones eficientes de datos no etiquetados.
Estas innovaciones han mejorado la capacidad de los modelos para hacer predicciones y clasificaciones más precisas en campos como la inteligencia artificial y el análisis de datos a gran escala. Por ejemplo, una investigación de 2024 aplicó autoencoders variacionales a datos clínicos y logró descubrir señales genéticas ocultas que mejoraron la predicción de enfermedades en múltiples biobancos.
Preprocesamiento de los datos para el modelado no supervisado
Si bien es común que el procesamiento de datos sea subestimado, es un aspecto esencial en el modelado no supervisado. Se trata de un proceso mediante el cual se transforman los datos en bruto a un formato más adecuado y más sencillo de comprender para el algoritmo.
Eso permite identificar y corregir datos faltantes, errores o inconsistencias que puedan afectar la precisión de los resultados.
Recordemos que el hecho de que los datos de entrada sean relevantes y de calidad constituye una característica necesaria para la obtención de predicciones precisas en las cuales se pueda confiar.
El preprocesamiento de datos sigue siendo vital, con nuevas técnicas como Transformada de Fourier y Mapas Autoorganizados (SOM), que ayudan a reducir el ruido y mejoran la calidad de los datos antes de la modelización.
Mejorar la precisión de otros algoritmos de aprendizaje mediante el preprocesamiento
El preprocesamiento de los datos es esencial, ya que permite mejorar la precisión de los algoritmos. Técnicas más recientes como Mapas Autoorganizados (SOM) y la Transformada de Fourier se están utilizando para reducir el ruido y mejorar la calidad de los datos, particularmente en sectores como la climatología y el análisis de señales. Esto asegura que los algoritmos puedan hacer predicciones más precisas y confiables.
Esto se puede observar de forma clara cuando los datos no están normalizados. En esos casos, ciertas características tendrán un peso mayor que otras en la modelación, lo cual puede afectar la precisión.
Esto es a causa de los ruidos, los valores atípicos y nulos y otras anomalías que posean los datos en bruto y que puedan tener un efecto negativo sobre el rendimiento del modelo.
En síntesis, el preprocesamiento actúa como la primera línea de defensa para garantizar que los algoritmos de aprendizaje—ya sean supervisados o no—reciban datos depurados, homogéneos y representativos.
Al eliminar ruido, normalizar magnitudes y tratar valores atípicos, se allana el camino para modelos más estables y precisos, capaces de generalizar con confianza incluso en escenarios complejos como la climatología o el análisis de señales.
Entonces, los puntos claves para mejorar la precisión de otros algoritmos de aprendizaje mediante el preprocesamiento son:
- Normalización consistente: iguala escalas numéricas para que todas las variables influyan de forma equilibrada en la modelación.
- Reducción de ruido con técnicas avanzadas: Mapas Autoorganizados (SOM) y la Transformada de Fourier aíslan patrones útiles y filtran señales irrelevantes.
- Tratamiento de valores atípicos y nulos: minimiza su impacto negativo sobre la precisión y evita sesgos en las predicciones.
- Mejor calidad de datos, mejor rendimiento: datos limpios mejoran la estabilidad de los modelos y disminuyen la varianza en resultados.
- Base sólida para la generalización: un preprocesamiento riguroso permite que los algoritmos aprendan conceptos subyacentes, elevando la fiabilidad de las predicciones en dominios críticos.
Comparación entre los resultados y análisis de tendencias en modelos estadísticos
La estadística y el ML son dos fenómenos que se relacionan entre sí. Esto se debe, por un lado, a que la estadística es un elemento esencial para el correcto análisis de los datos.
A través de la estadística, es posible visualizar los datos con el objetivo de encontrar patrones que no se habían notado, construir modelos de datos, analizar datos brutos e inferir resultados.
Por otra parte, a través del machine learning, es posible encontrar patrones y tendencias en los modelos estadísticos, de modo que con la información recabada se puedan tomar decisiones basadas en los datos.
Algo que es muy utilizado por las empresas es lo que se conoce como análisis de series temporales. Este se ha beneficiado enormemente del aprendizaje automático, con modelos avanzados como LSTM (Long Short-Term Memory), que permiten una mejor predicción y comprensión de datos secuenciales y de series temporales
Estos datos pueden ser tanto la venta de un producto como el precio cambiante de las acciones en un mercado.
De ese modo, a través del ML se puede acceder a un correcto análisis de las tendencias que se encuentran en esas estadísticas y comparar para tener más herramientas a la hora de tomar una decisión.
Además, el machine learning ofrece la posibilidad de mejorar el análisis de series temporales a través de la predicción. Esto se debe a que cuenta con la capacidad de anticipar un comportamiento futuro basándose en patrones y tendencias de datos históricos.
Con una técnica de aprendizaje automático se tendrá también la oportunidad de encontrar patrones ocultos en las tendencias que no pueden ser percibidos, en muchas ocasiones, por humanos.
Metodología para elegir la técnica correcta, según la necesidad
Elegir la técnica correcta de aprendizaje automático es una tarea importante debido a que la elección dependerá mucho de la tarea a realizar. Como mencionamos anteriormente, por su característica de contar con datos no etiquetados, el aprendizaje no supervisado se utiliza mayormente para tareas complejas.
Rendimiento
Para elegir la técnica adecuada, es necesario tener en cuenta algunos factores como por ejemplo el rendimiento. Este último se relaciona con la calidad de los resultados que arroja un modelo.
Explicabilidad de los resultados
Pero no es lo único a tener en cuenta, ya que no siempre es el rendimiento lo que debe motivar nuestra decisión. Otro factor a considerar es la explicabilidad de los resultados, es decir, que sea posible argumentarlos. De nada sirve tener buenos datos si los datos que requiere no son demasiado difíciles de expresar o interpretar.
A su vez, antes de elegir, es importante tener en cuenta la complejidad del modelo de aprendizaje no supervisado, el tamaño del conjunto de los datos y la dimensionalidad.
Preguntas frecuentes sobre aprendizaje no supervisado
¿Cómo se calcula el ROI de un proyecto de aprendizaje no supervisado en el sector TIC?
Mide el ahorro directo (p. ej., -20 % en costes operativos o fraude evitado) y el ingreso incremental generado por nuevos segmentos o detección temprana de riesgos, y divídelo entre la inversión en datos, nube y talento especializado. Combinar KPIs financieros con métricas de IA (Silhouette Score, DB Index) crea un modelo de “valor incremental” que facilita justificar el ROI aprendizaje no supervisado ante la dirección.
¿Qué métricas se utilizan para evaluar la calidad de un modelo de clustering en producción?
Para modelos no etiquetados, los decisores suelen revisar Silhouette Score, Davies-Bouldin Index y Calinski-Harabasz para cuantificar cohesión y separación de grupos, además de monitorear drift con distancia de Wasserstein. Estas métricas de validación de modelos no supervisados permiten detectar degradación temprana sin datos etiquetados.
¿Cómo garantizar el cumplimiento de GDPR y otras normativas al procesar datos no etiquetados?
Implementa anonimización diferencial o síntesis de datos, mantén trazabilidad completa (data lineage) y aplica revisiones de riesgo antes de cada iteración del modelo. Adoptar un framework de gobierno de datos con políticas “privacy-by-design” asegura el cumplimiento GDPR IA y evita sanciones costosas.
¿Qué prácticas de MLOps agilizan el despliegue continuo de modelos no supervisados en nube híbrida?
Automatiza pipelines CI/CD con reentrenamiento programado, almacena variables en un feature store versionado y monitoriza data drift en tiempo real; así se reducen tiempos de entrega de semanas a horas. Integrar contenedores Kubernetes y serverless facilita la escalabilidad elástica de los modelos no supervisados en entornos multicloud.