

No fue la robótica ni el reconocimiento facial lo que llevó a la inteligencia artificial al centro de la conversación en las empresas, sino los modelos de lenguaje grande (LLM, por sus siglas en inglés). En muy pocos años, pasaron de ser un experimento de laboratorio a convertirse en el motor invisible detrás de los chatbots.
Hoy, el mercado de chatbots se encuentra dominado por cuatro de los desarrolladores más grandes, según DataStudios. Estos son:
- ChatGPT, de OpenAI; con un promedio de 122.6 millones de usuarios diarios
- Gemini, de Google; con un estimado de 284 millones de visitas mensuales
- Copilot, de Microsoft; que captura un 14% del mercado de chatbots con IA
- Claude, de Antropic; con unos pocos millones de usuarios activos
En total, DataStudios estima que más de 987 millones de personas en todo el mundo utilizan chatbots de IA (en todas las plataformas) en 2025; una cifra impresionante teniendo en cuenta los pocos años que pasaron desde la popularización de ChatGPT ¿y tú? ¿dónde aplicas inteligencia artificial?
Índice de temas
¿Qué es un modelo de lenguaje grande (LLM)?
Basados en redes neuronales, los modelos de lenguaje grande son capaces de comprender y generar texto en lenguaje natural con un nivel de fluidez idéntico al de los humanos. Según la enciclopedia Britannica, sus algoritmos son capaces de ejecutar tareas de procesamiento de lenguaje natural (NLP), algo que sucede a la generación de texto.
Gracias a su potencial, los LLM proyectan un crecimiento del 20.57% entre 2025 y 2030. Sin embargo, expertos como Samuel R. Bowman, académico de la CIMS, advierte que muchas de sus capacidades emergen de forma impredecible y aún no existen métodos confiables para entender ni controlar su funcionamiento.
Historia de LLM: del pasado a nuestros días
En sus inicios durante la década de 1970, los modelos largos de lenguaje buscaban crear sistemas expertos basados en reglas predefinidas, aunque sin mucho éxito; dice una publicación de Open Educational Resourses (OER). Eran modelos más simples,capaces de comprender y generar texto básico.
No fue sino hasta el siglo XXI donde se introdujeron los primeros embeddings, los cuales permitieron realizar codificaciones semánticas mucho más efectivas. Más tarde, éstos abrieron camino al desarrollo de los transformers, una arquitectura fundamental para comprender a los LLM modernos.

En una etapa temprana, los modelos grandes de lenguaje eran relativamente simples, entrenados para predecir la siguiente palabra en una secuencia de texto mediante un aprendizaje “auto-supervisado”. Esto sentó las bases para un avance acelerado hacia modelos como GPT-4.
Desarrollado por OpenAI, sus más de 1.76 billones de parámetros le permiten comprender contextos mucho más amplios y generar respuestas más coherentes y precisas.
Hoy, los LLM están integrados en infinidad de aplicaciones, tales como:
- Plataformas de traducción automática
- Generación creativa de contenidos
- Producción de material audiovisual
- Producción de texto creativo
Sin embargo, sus avances y capacidad de aplicaciones plantean desafíos igual de importantes hacia el interior de la comunidad tecnológica. El mantenimiento de sus estructuras demanda mucha energía, lo cual pone en debate el riesgo ecológico de la inteligencia artificial en materia de sostenibilidad.
Desde una perspectiva educativa, los son propensos a generar “alucinaciones”, es decir, información falsa presentada como real. Esto requiere esfuerzos continuos para mejorar su interpretación y confiabilidad.
Propiedades de LLM
Los modelos de lenguaje grande poseen propiedades que han sido fundamentales en su éxito y versatilidad. Descúbrelas en el siguiente cuadro comparativo.
| Aspecto | Descripción |
| Complejidad y capacidad de procesamiento | Los mayores LLM, como ChatGPT, cuentan con cientos de miles de millones de parámetros que les permiten aprender patrones lingüísticos a gran escala. |
| Aprendizaje preentrenado | Entrenados con grandes volúmenes de datos antes de su afinación, estos modelos adquieren una comprensión general del lenguaje aplicable a múltiples contextos. |
| Contextualización | Los LLM analizan no solo palabras individuales, sino el contexto completo para entender significados profundos y generar respuestas coherentes. |
Arquitectura de LLM
La arquitectura de los LLM está compuesta por tres pilares fundamentales:
Transformers
La arquitectura subyacente en muchos LLM se basa en la red neuronal denominada transformador, o transformers en inglés. Esta arquitectura se destaca por su capacidad para procesar y entender secuencias de datos, como frases o párrafos, de manera eficiente.
Capas apiladas
A su vez, los modelos grandes suelen tener múltiples capas apiladas de transformadores. Cada una aprende representaciones cada vez más abstractas del lenguaje, permitiendo una comprensión jerárquica y compleja de las estructuras lingüísticas.

Atención
En tanto, la atención es una característica clave de los transformadores, ya que permite al modelo asignar pesos a diferentes partes de la entrada, concentrándose en la información más relevante. Esto mejora la capacidad del modelo para procesar secuencias largas de manera efectiva.
Entrenamiento y downstream tasks
El entrenamiento de modelos grandes de lenguaje y sus tareas secundarias, conocidas como downstream tasks, son procesos clave que explican la versatilidad y el rendimiento de estos modelos.
Aprendizaje preentrenado
Los LLM se entrenan en una tarea de “preentrenamiento” donde se exponen a enormes cantidades de datos lingüísticos. Durante esta fase, el modelo aprende patrones, estructuras y contextualizaciones del lenguaje.
Afinamiento
Después del preentrenamiento, los modelos pueden ser afinados para tareas específicas. Este proceso implica entrenar el modelo en conjuntos de datos más pequeños y concretos para adaptarlo a una tarea particular, como traducción, clasificación de sentimientos o resumen de texto.
Traducción automática
Los LLM entrenados pueden aplicarse a la tarea de traducción automática, utilizando la comprensión contextual del lenguaje para producir traducciones más precisas y naturalmente sonantes.
Clasificación de texto
Los modelos pueden ser afinados para tareas de clasificación de texto, como análisis de sentimientos o categorización de temas. Su capacidad para entender contextos complejos mejora la precisión en estas tareas.
Generación de texto creativo
Asimismo, los LLM pueden ser utilizados para generar contenido creativo, desde historias hasta poemas, al aprovechar su capacidad para comprender y generar texto coherente y contextualizado.
Resumen de texto
En tareas de resumen automático, los modelos pueden condensar información relevante de un documento o artículo, manteniendo la esencia del contenido original.
Interacción con el usuario
Los LLM se utilizan en asistentes virtuales y chatbots para mejorar la interacción humano-máquina. Su capacidad para entender el contexto facilita respuestas más naturales y útiles.
Funcionalidades en el ámbito empresarial
Los LLM tienen un pronóstico de crecimiento tal que se proyecta van a crecer en tamaño de mercado un 2.5 veces en solo cinco años. Dice la consultora Mordor Intelligence que los modelos de lenguaje largo tienen un market size de US$ 8 310 millones para 2025; y alcanzará los US$ 21 170 millones en 2030.

Los atractivos del LLM para tener una CAGR del 20.57% son muchos, principalmente en lo que respecta al segmento empresarial a nivel productivo, tecnológico y financiero.
Uso de los LLM a nivel empresarial
Lo que en su momento las empresas de desarrollo de IA utilizaban para investigar, como es el caso de las arquitecturas multimodales que procesan texto e imágenes; hoy son una oferta comercial en sí misma. Pero existen muchas más:
- Procesamiento automático de lenguaje natural: mejora la capacidad empresarial para analizar grandes cantidades de datos de texto y comprender la retroalimentación del cliente.
- Generación de contenido y redacción automática: automatiza la creación de informes, correos electrónicos y descripciones de productos, ahorrando tiempo y recursos.
- Asistentes virtuales y chatbots: facilita la interacción en el servicio al cliente al proporcionar respuestas precisas y resolver problemas básicos sin intervención humana.
- Traducción automática mejorada: ofrece traducciones más precisas y naturales, beneficiando a empresas con operaciones internacionales.
- Análisis de grandes conjuntos de datos: permite la extracción de patrones y tendencias útiles para la toma de decisiones y la predicción de tendencias del mercado.
- Seguridad y detección de fraude: aplicación en la identificación de amenazas de seguridad y actividades fraudulentas, mejorando la seguridad cibernética y la gestión de riesgos.
Modelos largos de lenguaje y NLP
Hablar de inteligencia artificial es un fenómeno mainstream hoy día, por lo que es de suma utilidad saber de qué se habla cuando se mencionan términos como LLM y lenguaje de procesamiento natural.
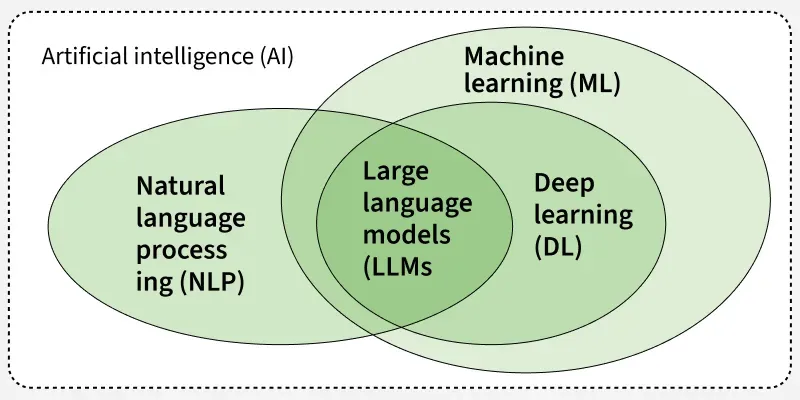
Dice la organización Geeks for Geeks que ambos términos tienen un único fin: “ayudar a las máquinas a comprender e interactuar con el lenguaje humano”. Sin embargo, existen lugares en donde pueden diferenciarse.
Diferencias del NLP con el LLM
El NLP se enfoca en que las máquinas comprendan e interpreten el lenguaje humano a través de sistemas basados en reglas y modelos de aprendizaje profundo. Un modelo conocido es la API de Google, capaz de detectar sentimientos y asignar categorías al contenido que se indexa en la web.
En cambio, los LLM representan un subconjunto del aprendizaje de lenguaje natural que se entrena con enormes cantidades de datos. Entre los más populares, chatGPT es uno de ellos. Es capaz de generar texto, entender contextos y razonar ante un escenario determinado.
Otras diferencias son la escala y los recursos que requiere cada uno para funcionar:
- NLP puede implementarse con hardware y datos para tareas específicas
- LLM demanda grandes volúmenes de datos e infraestructura
Además, los NLP tienden a enfocarse en soluciones específicas y estructuradas, mientras que los LLM sobresalen en tareas que requieren generalización y creatividad.
Similitudes entre LLM y NLP
Tanto NLP como LLM buscan que las máquinas puedan entender y procesar el lenguaje humano para obtener una interacción humano/máquina menos robotizada.
Con ayuda de la lingüística computacional, el aprendizaje automático y los modelos estadísticos que analizan y generan texto; los robots son capaces de replicar respuestas muy parecidas a las que daría una persona.
Sin embargo, mientras NLP utiliza arquitecturas de aprendizaje profundo para tareas concretas, los LLM constituyen una evolución más avanzada de estas tecnologías.
Pros y contras de usar LLM a nivel empresarial
A modo de comprender y graficar a las ventajas e inconvenientes de utilizar modelos de lenguaje largo a nivel corporativo, ten a mano la siguiente infografía con una serie de puntos que tu equipo TI deberá considerar.

Ética y sostenibilidad en el uso de LLM
Como habíamos adelantado, la sostenibilidad y la información falsa son dos de los problemas que más revuelan en el segmento de los LLM y la inteligencia artifciial en sí.
Sostenibilidad e IA: un tema que preocupa
Profesionales de IA y organizaciones medioambientales alzan la voz ante el uso de electricidad y agua que los datacenters que alimentan a varias inteligencias artificiales están demandando.
Según una publicación del Instituto Tecnológico de Massachussetts (MIT), las proyecciones sobre la demanda futura de energía para impulsar la IA son inciertas y varían ampliamente, pero se estima que los centros de datos podrían representar entre el 6% y el 12% del consumo total de electricidad solo en Estados Unidos.

Si bien hoy no es la porción de pastel más grande de la distribución eléctrica en materia tecnológica, la IA y los centros de datos es la más urgente; dice el MIT, Porque su crecimiento y concentración geográfica es el más rápido de los tres, si se lo compara con los autos eléctricos y otras tecnologías.
Misleading content: Cómo la IA engaña en sus respuestas
Organizaciones como la UNESCO alentan a otras ONGs e incluso gobiernos del mundo a promulgar leyes locales e invertir en el desarrollo de la inteligencia artificial. En este caso, el documento “Ética de la Inteligencia Artificial” publicado por la organización de ONU plantea que la IA puede reproducir sesgos y contribuir a las desigualdades en la sociedad.
Los desarrolladores de IA deben entonces promover la responsabilidad en la generación de contenido e implementar mecanismos de supervisión, auditoría y evaluación ética durante todo el ciclo de vida de los sistemas de IA para prevenir daños sociales derivados de la desinformación.
Casos de uso destacados de LLM
Como se relató a lo largo del artículo, los modelos grandes de lenguajes se pueden aplicar en diferentes industrias y de diversas formas, sin embargo, hoy en día, las más utilizadas son dos:
Chatbots
Múltiples empresas que reciben cientos de consultas al día de parte de sus clientes comenzaron a implementar chatbots basados en LLM para resolver las dudas más frecuentes. En estos casos, los usuarios explican por escrito lo que está sucediendo y el bot responde.
Plataformas de creación de contenido
A su vez, los LLM se encuentran en las plataformas de creación de contenido, que escriben desde noticias hasta poemas, pasando por ensayos universitarios y guiones, según lo que pida el cliente. Cuanto más específico sea el humano, más efectivo será el algoritmo.
El futuro de los modelos grandes de lenguaje
El futuro de los modelos grandes de lenguaje es un área emocionante y en constante evolución en la investigación de inteligencia artificial, principalmente gracias a las nuevas tendencias:
- Modelos aún más grandes: a medida que la capacidad computacional aumenta, es probable que veamos modelos de lenguaje aún más grandes que los existentes.
- Modelos especializados: en lugar de crear modelos grandes y genéricos, podríamos ver una tendencia hacia modelos especializados para tareas específicas.
- Mejora en eficiencia computacional: se espera que se realicen avances significativos en la eficiencia de los modelos, permitiendo que modelos más pequeños logren resultados similares a los de modelos más grandes.
- Modelos multimodales: la integración de información de múltiples modalidades, como texto, imágenes y audio, podría convertirse en una norma.
- Transparencia y explicabilidad: se espera que haya avances en técnicas que mejoren la interpretabilidad de los modelos de lenguaje.
Preguntas frecuentes sobre modelos de lenguaje grande
¿Qué factores debe considerar una empresa al elegir un modelo de lenguaje grande (LLM)?
Debe evaluar precisión, escalabilidad, privacidad de datos, compatibilidad con su infraestructura y disponibilidad de soporte técnico. Considerar LLMs open source vs comerciales es clave para controlar costos y personalización.
¿Cuál es el costo total de propiedad (TCO) al implementar un LLM empresarial?
El TCO incluye costos de licenciamiento, infraestructura en la nube o on-premise, entrenamiento, mantenimiento y talento especializado. Ignorar estos elementos puede impactar la rentabilidad del proyecto de IA.
¿Qué marco de gobernanza de IA es recomendable al usar LLM en entornos corporativos?
Se sugiere adoptar políticas de IA responsable que aborden sesgos, seguridad, monitoreo continuo y uso ético. Frameworks como NIST AI RMF y OECD AI Principles pueden guiar la implementación.
¿Qué regulaciones deben considerar las empresas que usan LLM en Latinoamérica y la Unión Europea?
En la UE aplica la AI Act (2025), que clasifica riesgos y exige transparencia. En LATAM, países como Brasil y México avanzan en leyes de protección de datos que impactan el uso de IA y modelos generativos.

